De-rendering Stylized Texts

Wataru Shimoda1, Daichi Haraguchi2, Seiichi Uchida2, Kota Yamaguchi1
1CyberAgent.Inc, 2 Kyushu University
Abstruct
Editing raster text is a promising but challenging task. We propose to apply text vectorization for the task of raster text editing in display media, such as posters, web pages, or advertisements. In our approach, instead of applying image transformation or generation in the raster domain, we learn a text vectorization model to parse all the rendering parameters including text, location, size, font, style, effects, and hidden background, then utilize those parameters for reconstruction and any editing task. Our text vectorization takes advantage of differentiable text rendering to accurately reproduce the input raster text in a resolution-free parametric format. We show in the experiments that our approach can successfully parse text, styling, and background information in the unified model, and produces artifact-free text editing compared to a raster baseline.
Video
Overview of the proposed model
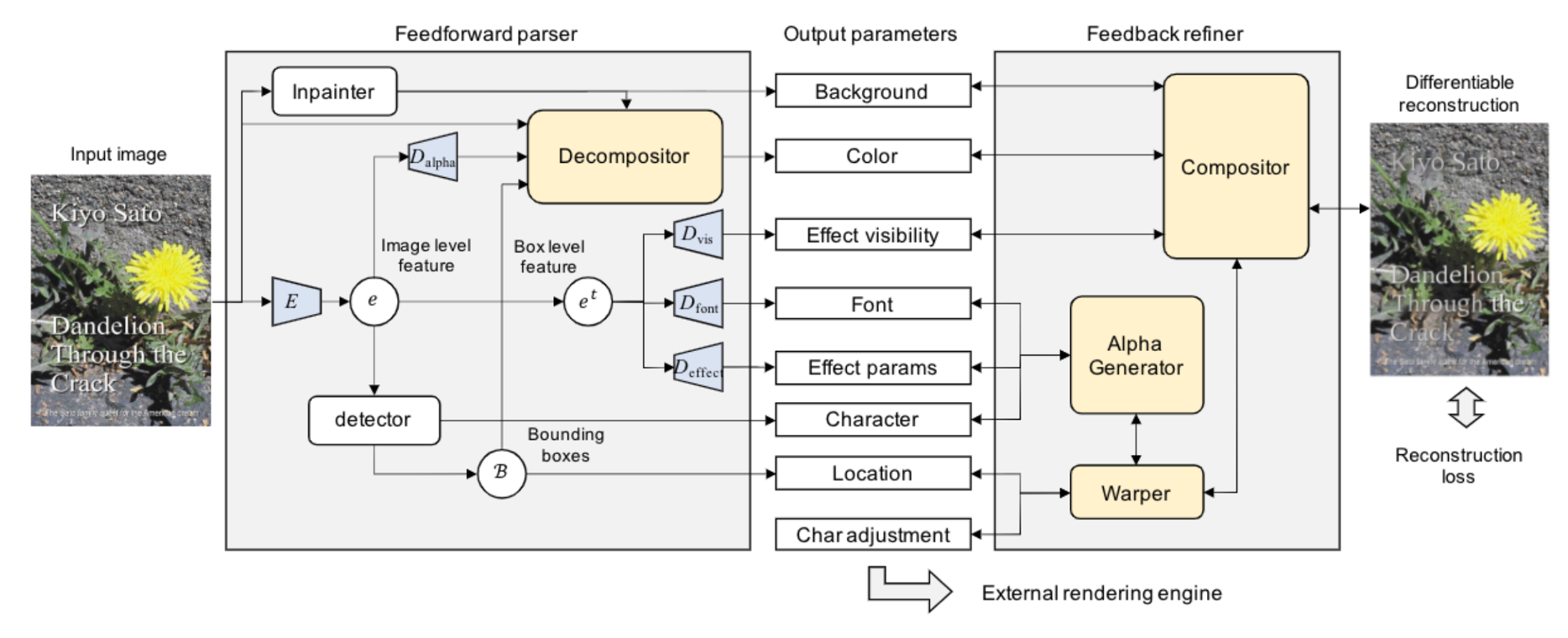
Optimization via differentiable text rendering


Text edit Demo


Results1

Results2

Citation
@InProceedings{Shimoda_2021_ICCV,
author = {Shimoda, Wataru and Haraguchi, Daichi and Uchida, Seiichi and Yamaguchi, Kota},
title = {De-Rendering Stylized Texts},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {1076-1085}
}