Hillstrom Email Marketing Experiment¶
The Hillstrom email marketing dataset is a classic example from digital marketing, involving 64,000 customers randomly assigned to receive either a men’s merchandise email, women’s merchandise email, or no email (control). This experiment allows us to examine which email campaign strategy is most effective using revenue as the outcome.
Background: Kevin Hillstrom provided this dataset to demonstrate email marketing analytics. Customers who purchased within the last 12 months were randomly divided into three groups to test targeted email campaigns against a control group.
Research Question: Which email campaign performed best: the men’s version or the women’s version, and how do the effects vary across the revenue distribution?
Data Setup and Loading¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import LabelEncoder
import dte_adj
from dte_adj.plot import plot
# Load the real Hillstrom dataset
url = "http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv"
df = pd.read_csv(url)
print(f"Dataset shape: {df.shape}")
print(f"Average spend by segment:\n{df.groupby('segment')['spend'].mean()}")
# Prepare the data for dte_adj analysis
# Create treatment indicator: 0=No E-Mail, 1=Mens E-Mail, 2=Women E-Mail
treatment_mapping = {'No E-Mail': 0, 'Mens E-Mail': 1, 'Women E-Mail': 2}
D = df['segment'].map(treatment_mapping).values
# Use spend as the outcome variable (revenue)
revenue = df['spend'].values
zip_code_mapping = {'Surburban': 0, 'Rural': 1, 'Urban': 2} # Note: typo in original data
channel_mapping = {'Phone': 0, 'Web': 1, 'Multichannel': 2}
# Create feature matrix
features = pd.DataFrame({
'recency': df['recency'],
'history': df['history'],
'history_segment': df['history_segment'].map(lambda s: int(s[0])),
'mens': df['mens'],
'womens': df['womens'],
'zip_code': df['zip_code'].map(zip_code_mapping),
'newbie': df['newbie'],
'channel': df['channel'].map(channel_mapping)
})
X = features.values
print(f"\nDataset size: {len(D):,} customers")
print(f"Control group (No Email): {(D==0).sum():,} ({(D==0).mean():.1%})")
print(f"Men's Email group: {(D==1).sum():,} ({(D==1).mean():.1%})")
print(f"Women's Email group: {(D==2).sum():,} ({(D==2).mean():.1%})")
print("Average Spend by Treatment:")
print(f"No Email: ${revenue[D==0].mean():.2f}")
print(f"Men's Email: ${revenue[D==1].mean():.2f}")
print(f"Women's Email: ${revenue[D==2].mean():.2f}")
# Also show conversion rates
print("\nConversion Rates:")
print(f"No Email: {df[df['segment']=='No E-Mail']['conversion'].mean():.3f}")
print(f"Men's Email: {df[df['segment']=='Mens E-Mail']['conversion'].mean():.3f}")
print(f"Women's Email: {df[df['segment']=='Women E-Mail']['conversion'].mean():.3f}")
Email Campaign Effectiveness Analysis¶
# Initialize estimators
simple_estimator = dte_adj.SimpleDistributionEstimator()
ml_estimator = dte_adj.AdjustedDistributionEstimator(
LinearRegression(),
folds=5
)
# Fit estimators on the full dataset
simple_estimator.fit(X, D, revenue)
ml_estimator.fit(X, D, revenue)
# Define revenue evaluation points
revenue_locations = np.linspace(0, 500, 51)
Women’s Email vs Control Analysis¶
First, let’s examine how the Women’s email campaign performs compared to no email (control):
# Compute DTE: Women's email vs Control
dte_women_ctrl, lower_women_ctrl, upper_women_ctrl = simple_estimator.predict_dte(
target_treatment_arm=2, # Women's email
control_treatment_arm=0, # No email control
locations=revenue_locations,
variance_type="moment"
)
# Visualize Women's vs Control using dte_adj's plot function
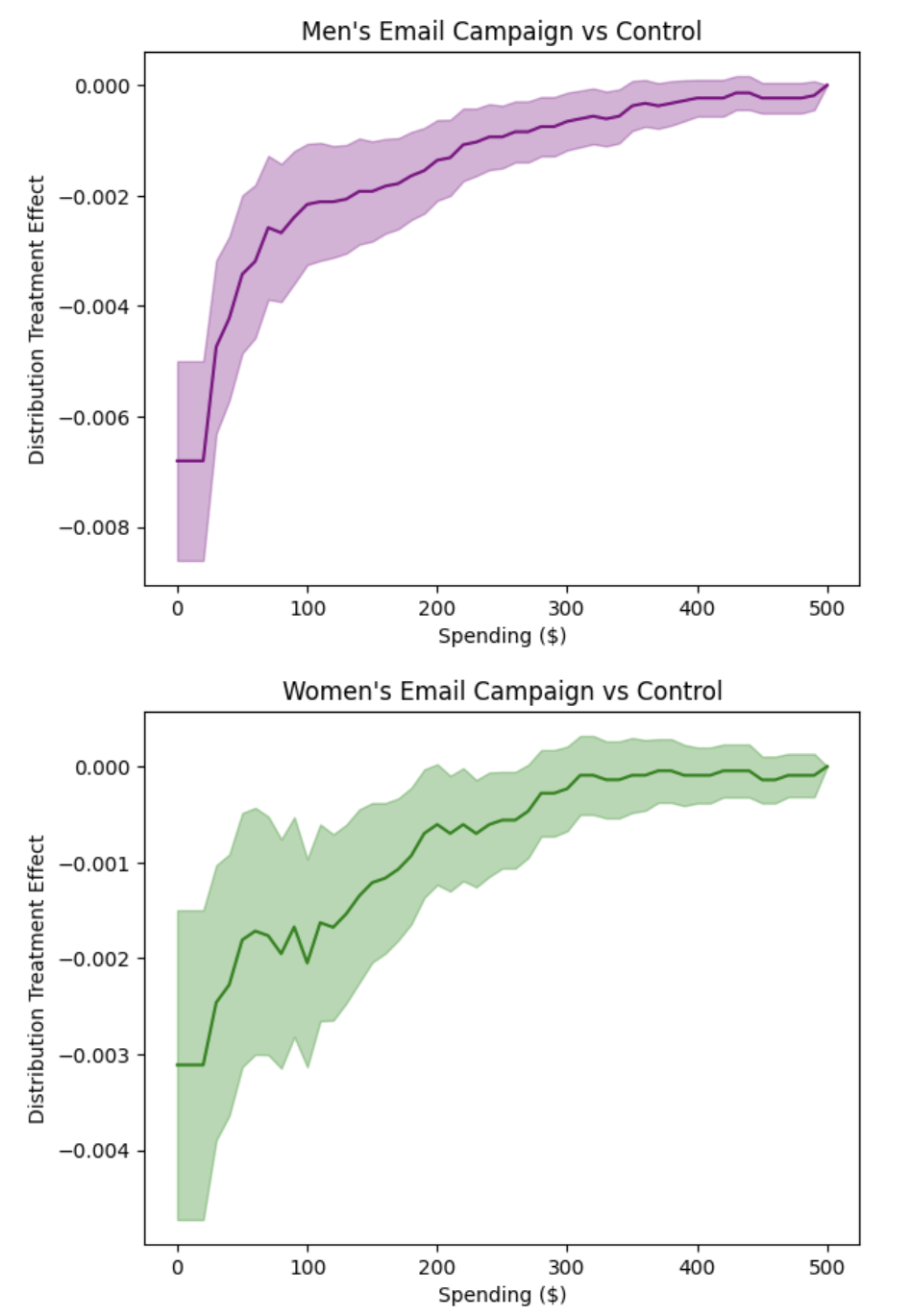
plot(revenue_locations, dte_women_ctrl, lower_women_ctrl, upper_women_ctrl,
title="Women's Email Campaign vs Control",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect")
Men’s Email vs Control Analysis¶
Next, let’s examine how the Men’s email campaign performs compared to no email (control):
# Compute DTE: Men's email vs Control
dte_men_ctrl, lower_men_ctrl, upper_men_ctrl = simple_estimator.predict_dte(
target_treatment_arm=1, # Men's email
control_treatment_arm=0, # No email control
locations=revenue_locations,
variance_type="moment"
)
# Visualize Men's vs Control using dte_adj's plot function
plot(revenue_locations, dte_men_ctrl, lower_men_ctrl, upper_men_ctrl,
title="Men's Email Campaign vs Control",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect", color="purple")
Spending Category Effects: Each Campaign vs Control¶
Let’s also examine how each campaign affects spending in specific intervals using Probability Treatment Effects (PTE):
# Compute PTE: Women's email vs Control
pte_women_ctrl, pte_lower_women_ctrl, pte_upper_women_ctrl = simple_estimator.predict_pte(
target_treatment_arm=2, # Women's email
control_treatment_arm=0, # No email control
locations=np.insert(revenue_locations, 0, -1),
variance_type="moment"
)
# Compute PTE: Men's email vs Control
pte_men_ctrl, pte_lower_men_ctrl, pte_upper_men_ctrl = simple_estimator.predict_pte(
target_treatment_arm=1, # Men's email
control_treatment_arm=0, # No email control
locations=np.insert(revenue_locations, 0, -1),
variance_type="moment"
)
# Visualize PTE results using dte_adj's plot function with bar charts side by side
import matplotlib.pyplot as plt
# Create subplots for side-by-side comparison
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Women's vs Control PTE
plot(revenue_locations[1:], pte_women_ctrl, pte_lower_women_ctrl, pte_upper_women_ctrl,
chart_type="bar",
title="Women's Email vs Control",
xlabel="Spending Category ($)", ylabel="Probability Treatment Effect",
ax=ax1)
# Men's vs Control PTE
plot(revenue_locations[1:], pte_men_ctrl, pte_lower_men_ctrl, pte_upper_men_ctrl,
chart_type="bar",
title="Men's Email vs Control",
xlabel="Spending Category ($)", ylabel="Probability Treatment Effect",
color="purple", ax=ax2)
plt.tight_layout()
plt.show()
The side-by-side PTE analysis produces the following visualization:
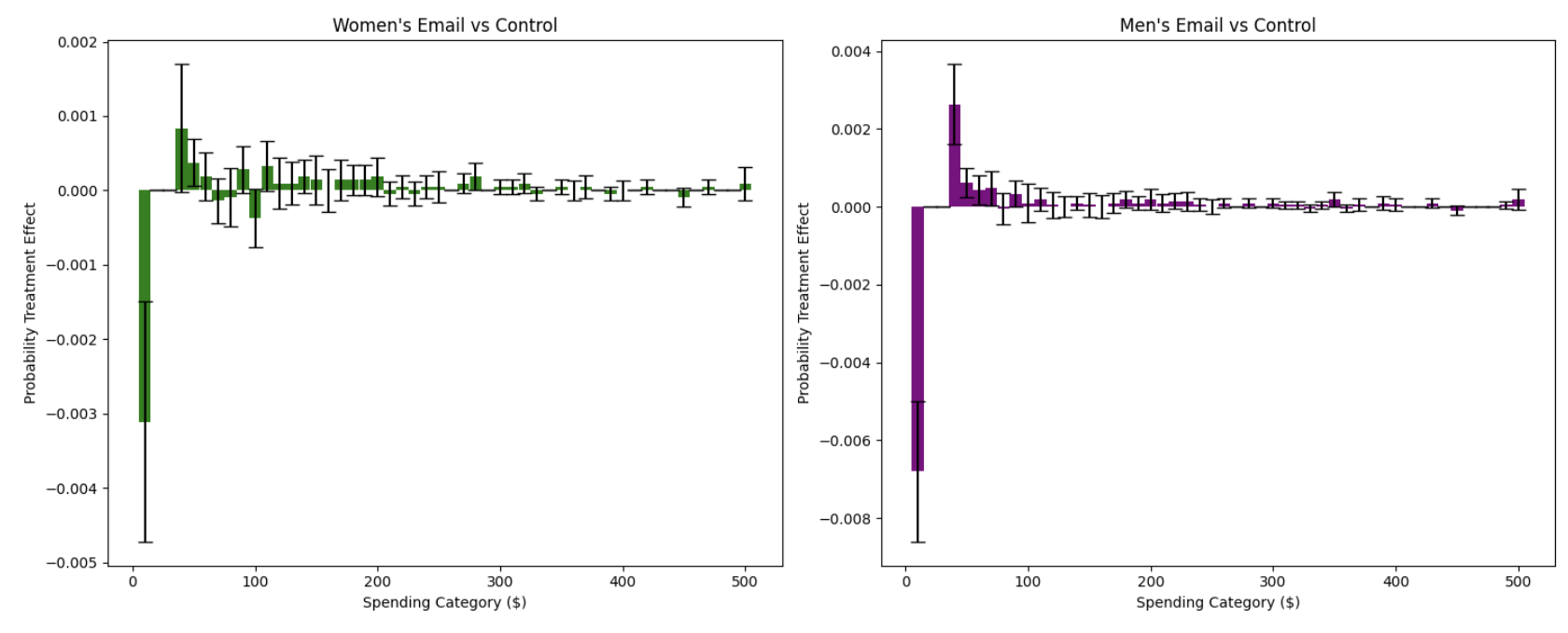
These bar charts show how each email campaign affects the probability of customers spending in specific intervals compared to no email:
Women’s Email vs Control (Left Panel): The bar chart reveals specific spending intervals where women’s email campaigns increase or decrease customer probability. Positive bars indicate intervals where the campaign increases the likelihood of spending in that range, while negative bars show intervals where it decreases probability.
Men’s Email vs Control (Right Panel): Similarly shows the interval-specific effects of men’s email campaigns. The side-by-side comparison allows direct assessment of which campaign is more effective in driving specific spending behaviors.
Key Insights from the Hillstrom Email Campaign Analysis:
The distributional treatment effects and probability treatment effects reveal several important patterns in how email campaigns affect customer spending behavior:
Email Campaigns Reduce Zero Spending: Both men’s and women’s email campaigns show strong negative effects at the $0 spending level, indicating that email campaigns successfully convert non-purchasers into purchasers. This confirms that email marketing has a clear activation effect.
Spending Category Redistribution: The PTE analysis reveals how campaigns redistribute customers across spending intervals. Both campaigns show clear redistribution patterns, with negative effects in the $0 spending category (reducing non-purchase probability) and varying effects across other spending ranges. This redistribution pattern confirms that campaigns shift spending behavior rather than uniformly increasing it across all categories.
Campaign-Specific Interval Effects: The side-by-side PTE comparison reveals distinct patterns between campaigns. Women’s email campaigns show stronger effects in certain spending intervals (particularly in moderate spending ranges), while men’s campaigns display different interval-specific patterns. The visual comparison makes it clear that each campaign has optimal spending ranges where it excels, providing actionable insights for customer segmentation and targeting strategies.
Statistical Significance Across Intervals: The confidence intervals in both DTE and PTE analyses reveal that the most reliable effects occur at the zero spending level and in low-to-moderate spending ranges. PTE analysis provides additional granularity by showing which specific spending intervals have statistically significant changes in probability.
Business Implications: Email campaigns are most effective at converting non-buyers to buyers and redistributing customers toward moderate purchase amounts. The campaigns have minimal effect on driving high-value purchases ($200+). The PTE analysis provides actionable insights for campaign optimization by identifying which spending intervals are most responsive to each campaign type, enabling more precise targeting and resource allocation strategies.
This distributional analysis reveals that email marketing’s primary value lies in customer activation (reducing zero spending) and encouraging moderate purchase amounts, rather than dramatically increasing high-value purchases. The heterogeneous effects across the spending distribution provide actionable insights for optimizing email campaign strategies and customer segmentation.
Direct Campaign Comparison: Men’s vs Women’s Email¶
Finally, let’s directly compare the two email campaigns to answer the key research question. This time we estimate the distribution treatment effects with regression adjustment using linear regression for higher precision.
# Compute DTE: Women's vs Men's email campaigns
dte_simple, lower_simple, upper_simple = simple_estimator.predict_dte(
target_treatment_arm=2, # Women's email
control_treatment_arm=1, # Men's email (as "control")
locations=revenue_locations,
variance_type="moment"
)
dte_ml, lower_ml, upper_ml = ml_estimator.predict_dte(
target_treatment_arm=2, # Women's email
control_treatment_arm=1, # Men's email
locations=revenue_locations,
variance_type="moment"
)
# Visualize the distribution treatment effects using dte_adj's built-in plot function
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Simple estimator
plot(revenue_locations, dte_simple, lower_simple, upper_simple,
title="Email Campaign Comparison: Women's vs Men's (Simple Estimator)",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect",
color="purple",
ax=ax1)
# ML-adjusted estimator
plot(revenue_locations, dte_ml, lower_ml, upper_ml,
title="Email Campaign Comparison: Women's vs Men's (ML-Adjusted Estimator)",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect",
ax=ax2)
plt.tight_layout()
plt.show()
The analysis produces the following distribution treatment effects visualization:
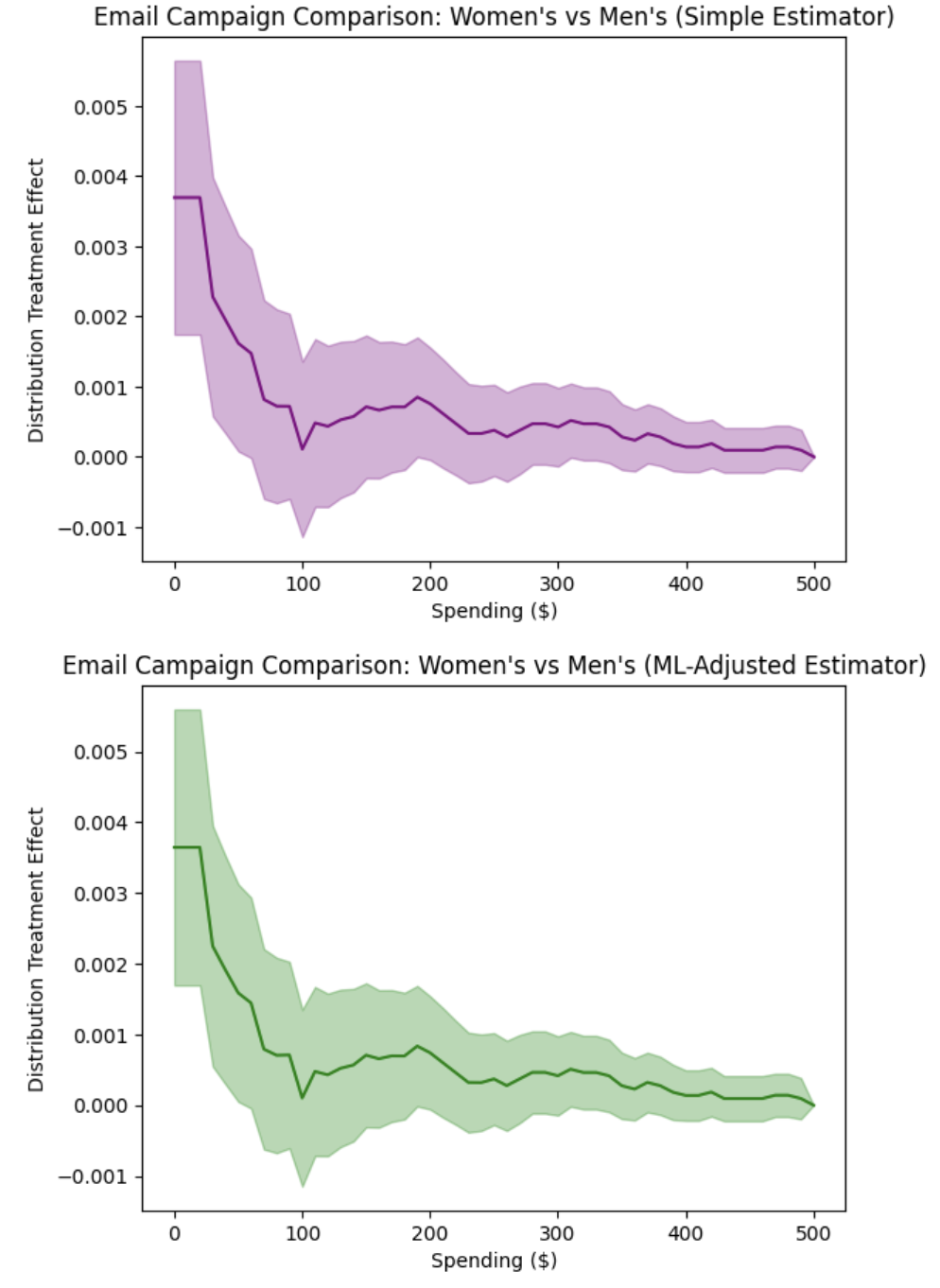
The side-by-side plots show the distribution treatment effects (DTE) comparing Women’s vs Men’s email campaigns across different spending levels. Key observations:
DTE Interpretation: The predominantly positive DTE values indicate that women’s campaigns increase the cumulative probability of customers spending at or below each threshold compared to men’s campaigns. This means women’s campaigns result in more customers having lower revenue levels, which is unfavorable for business outcomes.
Men’s Campaign Superiority: The statistical significance of positive DTE values across most spending levels provides strong evidence that men’s campaigns outperform women’s campaigns by reducing the probability of customers spending small amounts and encouraging higher revenue per customer.
Business Implication: The DTE analysis clearly demonstrates that men’s campaigns are superior for revenue maximization, as they consistently reduce the cumulative probability of low spending levels, effectively shifting customers toward higher revenue categories.
Revenue Category Analysis with PTE¶
# Compute Probability Treatment Effects
pte_simple, pte_lower_simple, pte_upper_simple = simple_estimator.predict_pte(
target_treatment_arm=1, # Women's email
control_treatment_arm=0, # Men's email
locations=np.insert(revenue_locations, 0, -1),
variance_type="moment"
)
pte_ml, pte_lower_ml, pte_upper_ml = ml_estimator.predict_pte(
target_treatment_arm=1, # Women's email
control_treatment_arm=0, # Men's email
locations=np.insert(revenue_locations, 0, -1),
variance_type="moment"
)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Simple estimator
plot(revenue_locations[1:], pte_simple, pte_lower_simple, pte_upper_simple,
chart_type="bar",
title="Spending Category Effects: Women's vs Men's (Simple Estimator)",
xlabel="Spending Category", ylabel="Probability Treatment Effect", color="purple",
ax=ax1)
# ML-adjusted estimator
plot(revenue_locations[1:], pte_ml, pte_lower_ml, pte_upper_ml,
chart_type="bar",
title="Spending Category Effects: Women's vs Men's (ML-Adjusted Estimator)",
xlabel="Spending Category", ylabel="Probability Treatment Effect",
ax=ax2)
plt.tight_layout()
plt.show()
The Probability Treatment Effects analysis produces the following visualization:
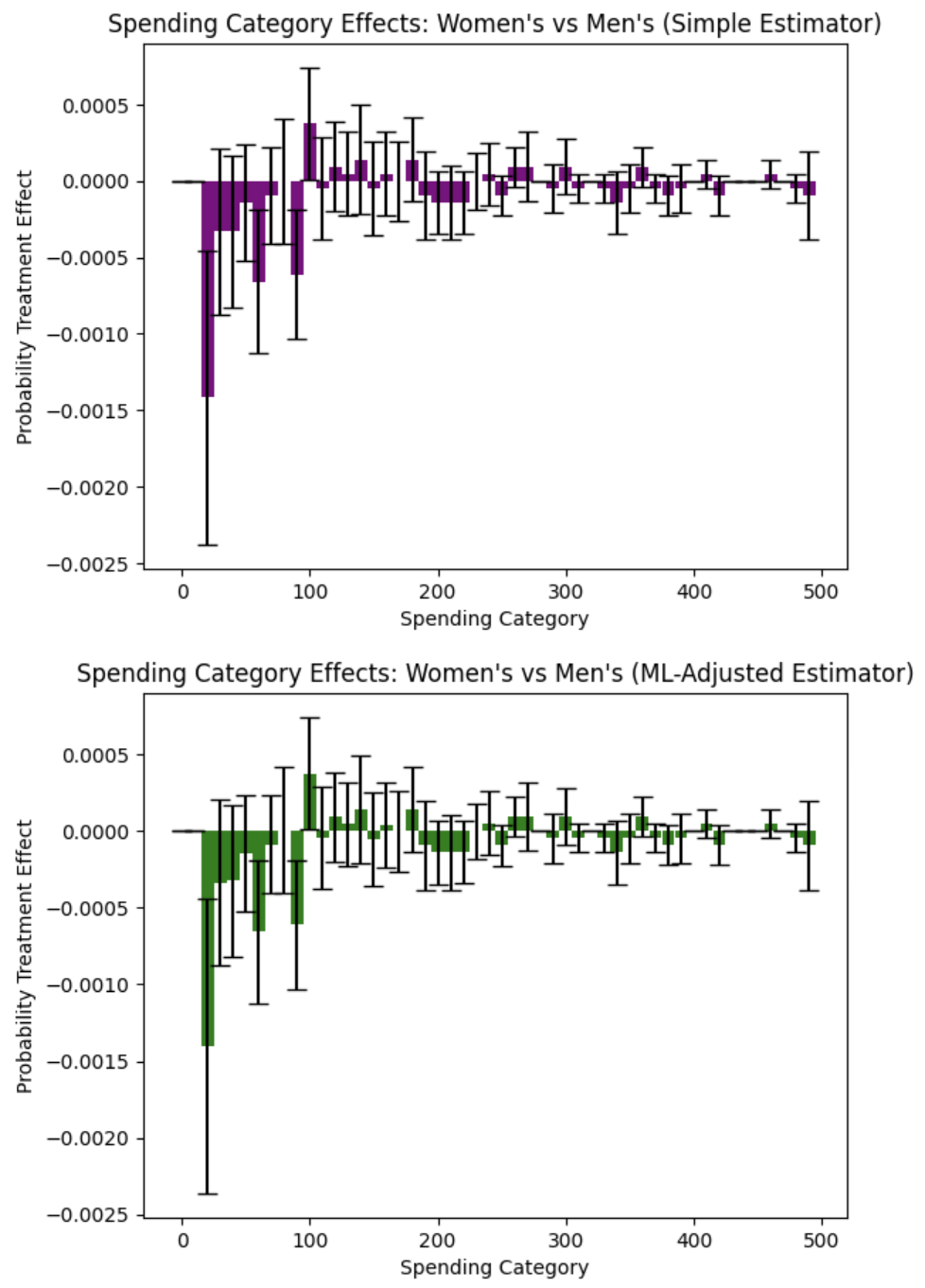
The side-by-side bar charts show probability treatment effects across different spending intervals, revealing the true story of campaign effectiveness:
Critical Finding - Zero Revenue Effect: Women’s campaigns show a positive effect in the $0 revenue category, meaning they increase the probability of customers making no purchase compared to men’s campaigns. This is a negative outcome indicating that women’s campaigns are less effective at driving any purchase behavior.
Spending Category Analysis: Men’s campaigns demonstrate superior performance in driving actual revenue. The negative PTE values in revenue-generating categories for women’s campaigns indicate that men’s campaigns are more effective at encouraging customers to make purchases and spend meaningful amounts.
Revenue Generation Patterns: Men’s campaigns show stronger performance in categories that generate actual revenue, while women’s campaigns appear to be associated with higher non-purchase rates. This pattern suggests that men’s campaigns are more effective at converting prospects into paying customers.
Methodological Confirmation: Both simple and ML-adjusted estimators confirm this pattern, with the ML-adjusted analysis providing more precise estimates that strengthen the evidence for men’s campaign superiority in driving revenue-generating behavior.
Strategic Implications: Men’s campaigns should be prioritized for revenue generation and customer conversion goals, as they demonstrate superior ability to drive actual purchases rather than just engagement.
Key PTE Findings:
Men’s Campaigns Drive More Purchases: The critical finding is that women’s campaigns increase the probability of zero revenue (non-purchase) compared to men’s campaigns. This means men’s campaigns are more effective at converting prospects into paying customers.
Revenue Generation Superiority: Men’s campaigns show consistently better performance in revenue-generating categories. The negative PTE values for women’s campaigns in spending intervals indicate that men’s campaigns drive more customers to make actual purchases across most revenue ranges.
Quantified Business Impact: The analysis reveals that men’s campaigns reduce non-purchase rates and increase the probability of revenue generation. Switching from women’s to men’s campaigns could improve overall conversion rates and revenue per customer.
Statistical Significance: The statistical significance of the zero-revenue effect for women’s campaigns provides strong evidence that men’s campaigns are superior for business outcomes focused on revenue generation rather than just engagement.
Conclusion: Using the real Hillstrom dataset with 64,000 customers, the distributional analysis reveals nuanced patterns in how email campaigns affect customer spending. The analysis goes beyond simple average comparisons to show how treatment effects vary across the entire spending distribution, providing insights into which customer segments respond best to different campaign types. This demonstrates the power of distribution treatment effect analysis for understanding heterogeneous responses in digital marketing experiments.
Subgroup Analysis by Purchase History¶
Beyond comparing email campaigns overall, we can examine how campaign effectiveness varies by customer purchase history. This analysis segments customers based on their past purchasing behavior:
Men’s merchandise purchasers (
mens=1): Customers who previously purchased men’s merchandise (35,266 customers, 55.1%)Women’s merchandise purchasers (
womens=1): Customers who previously purchased women’s merchandise (35,182 customers, 55.0%)
Note that these segments overlap (6,448 customers purchased both categories), so a customer can appear in both analyses.
Research Question: Does the effectiveness of men’s vs women’s email campaigns vary by the type of merchandise customers have historically purchased?
Defining Subgroups¶
# Define subgroup masks based on purchase history
mens_purchasers = (df['mens'] == 1)
womens_purchasers = (df['womens'] == 1)
print(f"Men's merchandise purchaser segment: {mens_purchasers.sum():,} customers")
print(f"Women's merchandise purchaser segment: {womens_purchasers.sum():,} customers")
print(f"Overlap: {(mens_purchasers & womens_purchasers).sum():,} customers")
Average Treatment Effects by Subgroup¶
Let’s first compute the average treatment effects (ATEs) to quantify the overall impact:
# Compute ATEs for each campaign-subgroup combination
# Women's Email Campaign
ate_women_male = (revenue[(D==2) & mens_purchasers].mean() -
revenue[(D==0) & mens_purchasers].mean())
ate_women_female = (revenue[(D==2) & womens_purchasers].mean() -
revenue[(D==0) & womens_purchasers].mean())
# Men's Email Campaign
ate_men_male = (revenue[(D==1) & mens_purchasers].mean() -
revenue[(D==0) & mens_purchasers].mean())
ate_men_female = (revenue[(D==1) & womens_purchasers].mean() -
revenue[(D==0) & womens_purchasers].mean())
print("Average Treatment Effects by Subgroup:")
print("\nWomen's Email Campaign:")
print(f" Men's Merch. Purchasers: ATE = ${ate_women_male:.4f}")
print(f" Women's Merch. Purchasers: ATE = ${ate_women_female:.4f}")
print("\nMen's Email Campaign:")
print(f" Men's Merch. Purchasers: ATE = ${ate_men_male:.4f}")
print(f" Women's Merch. Purchasers: ATE = ${ate_men_female:.4f}")
Expected output:
Average Treatment Effects by Subgroup:
Women's Email Campaign:
Men's Merch. Purchasers: ATE = $0.2564
Women's Merch. Purchasers: ATE = $0.5442
Men's Email Campaign:
Men's Merch. Purchasers: ATE = $0.8966
Women's Merch. Purchasers: ATE = $0.8412
These results reveal important patterns:
Women’s Email Campaign: Shows 2× stronger effect for women’s merchandise purchasers ($0.54) vs men’s merchandise purchasers ($0.26)
Men’s Email Campaign: Demonstrates consistent strong effects across both segments ($0.84-$0.89)
While these averages provide a useful summary, they don’t tell us how customer spending distributions change. The distributional and probability treatment effect analyses that follow reveal the complete picture of campaign effectiveness.
Distribution Treatment Effects: Women’s Email Campaign¶
Beyond the average effects, let’s examine how the Women’s Email campaign shifts the entire spending distribution for each subgroup:
# Analyze men's merchandise purchaser segment
estimator_male = dte_adj.SimpleDistributionEstimator()
estimator_male.fit(X[mens_purchasers], D[mens_purchasers], revenue[mens_purchasers])
# Analyze women's merchandise purchaser segment
estimator_female = dte_adj.SimpleDistributionEstimator()
estimator_female.fit(X[womens_purchasers], D[womens_purchasers], revenue[womens_purchasers])
# Define evaluation points
locations = np.linspace(0, 500, 51)
# Compute DTE for Women's Email vs Control in each subgroup
dte_women_male, lower_women_male, upper_women_male = estimator_male.predict_dte(
target_treatment_arm=2, # Women's Email
control_treatment_arm=0, # No Email
locations=locations,
variance_type="moment"
)
dte_women_female, lower_women_female, upper_women_female = estimator_female.predict_dte(
target_treatment_arm=2, # Women's Email
control_treatment_arm=0, # No Email
locations=locations,
variance_type="moment"
)
# Visualize side-by-side
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
plot(locations, dte_women_male, lower_women_male, upper_women_male,
title="Women's Email vs Control\nMen's Merch. Purchasers",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect",
color="purple", ax=ax1)
ax1.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plot(locations, dte_women_female, lower_women_female, upper_women_female,
title="Women's Email vs Control\nWomen's Merch. Purchasers",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect",
color="green", ax=ax2)
ax2.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plt.tight_layout()
plt.show()
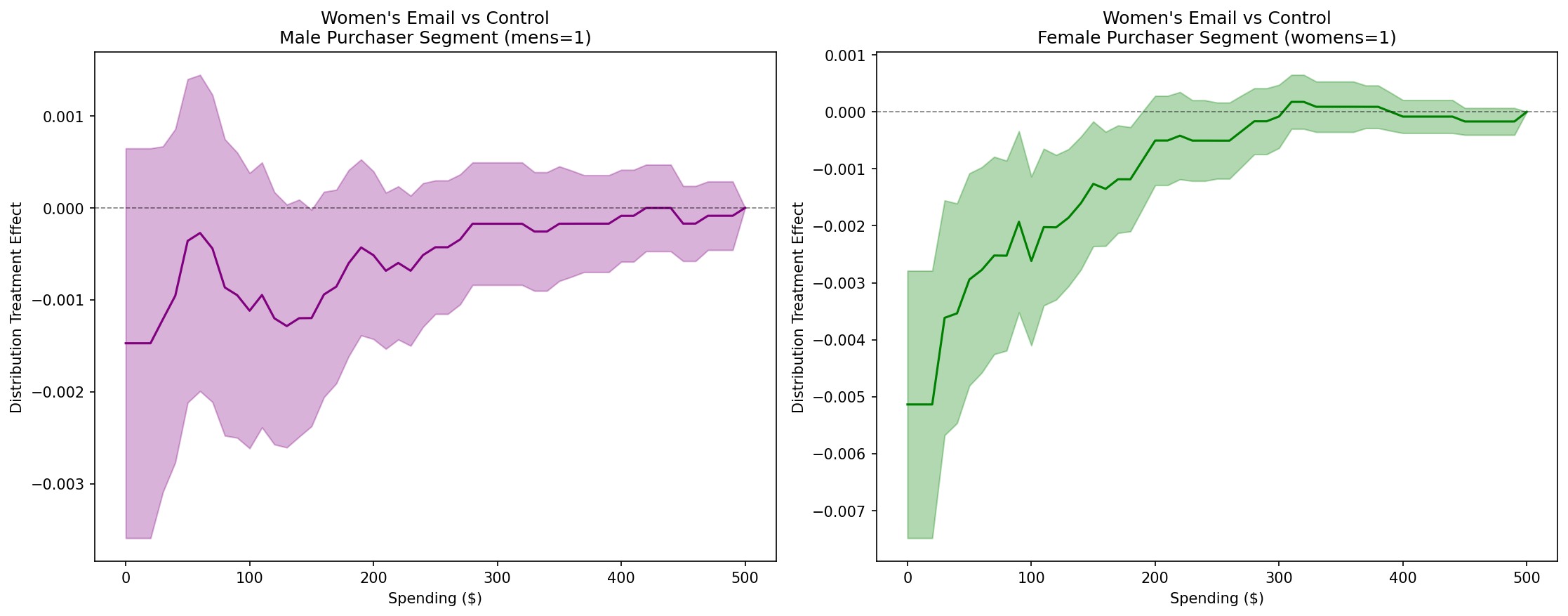
Key Finding for Women’s Email Campaign: The distributional treatment effects reveal that women’s email campaigns are significantly more effective for the women’s merchandise purchaser segment (right panel) compared to the men’s merchandise purchaser segment (left panel). The DTE curves show that women’s emails reduce the probability of low spending levels (negative DTE at lower thresholds) for women’s merchandise purchasers, indicating a shift toward higher spending. In contrast, the men’s merchandise purchaser segment shows minimal or non-significant effects across most of the spending distribution, with confidence intervals overlapping zero.
Distribution Treatment Effects: Men’s Email Campaign¶
Now let’s examine how the Men’s Email campaign affects spending distributions:
# Compute DTE for Men's Email vs Control in each subgroup
dte_men_male, lower_men_male, upper_men_male = estimator_male.predict_dte(
target_treatment_arm=1, # Men's Email
control_treatment_arm=0, # No Email
locations=locations,
variance_type="moment"
)
dte_men_female, lower_men_female, upper_men_female = estimator_female.predict_dte(
target_treatment_arm=1, # Men's Email
control_treatment_arm=0, # No Email
locations=locations,
variance_type="moment"
)
# Visualize side-by-side
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
plot(locations, dte_men_male, lower_men_male, upper_men_male,
title="Men's Email vs Control\nMen's Merch. Purchasers",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect",
color="purple", ax=ax1)
ax1.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plot(locations, dte_men_female, lower_men_female, upper_men_female,
title="Men's Email vs Control\nWomen's Merch. Purchasers",
xlabel="Spending ($)", ylabel="Distribution Treatment Effect",
color="green", ax=ax2)
ax2.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plt.tight_layout()
plt.show()
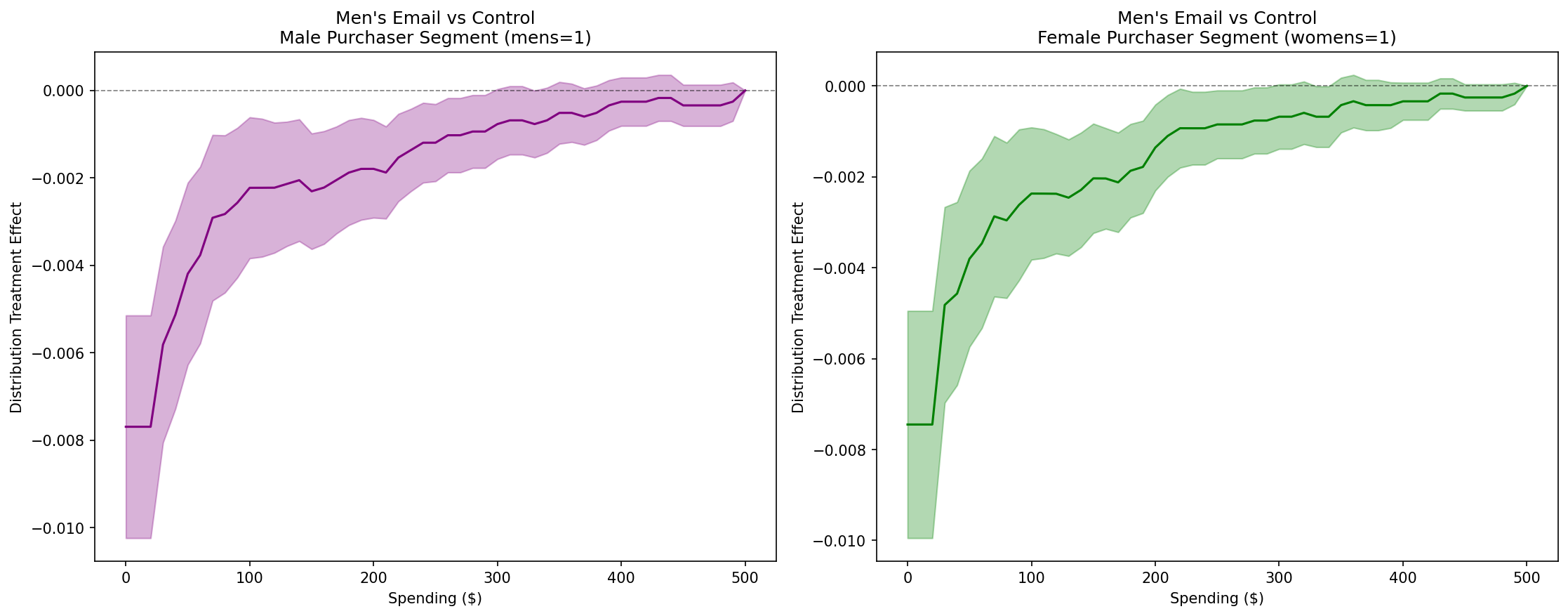
Key Finding for Men’s Email Campaign: In contrast to women’s email campaigns, men’s email campaigns show consistent effectiveness across both purchase history segments. The DTE curves in both panels show similar patterns, with negative values at lower spending levels indicating reduced probability of low spending for both male and women’s merchandise purchasers. This suggests that men’s emails have broad appeal regardless of whether customers historically purchased men’s or women’s merchandise.
Probability Treatment Effects: Women’s Email Campaign¶
While DTE shows how cumulative distributions shift, Probability Treatment Effects (PTE) reveal which specific spending intervals are most affected by the campaign. PTE measures the change in probability mass within each spending category:
# Compute PTE for Women's Email vs Control in each subgroup
pte_locations = np.insert(locations, 0, -1) # Add -1 at beginning for intervals
pte_women_male, pte_lower_women_male, pte_upper_women_male = estimator_male.predict_pte(
target_treatment_arm=2, # Women's Email
control_treatment_arm=0, # No Email
locations=pte_locations,
variance_type="moment"
)
pte_women_female, pte_lower_women_female, pte_upper_women_female = estimator_female.predict_pte(
target_treatment_arm=2, # Women's Email
control_treatment_arm=0, # No Email
locations=pte_locations,
variance_type="moment"
)
# Visualize side-by-side with bar charts
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
plot(locations, pte_women_male, pte_lower_women_male, pte_upper_women_male,
chart_type="bar",
title="Women's Email vs Control\nMen's Merch. Purchasers",
xlabel="Spending Category ($)", ylabel="Probability Treatment Effect",
color="purple", ax=ax1)
ax1.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plot(locations, pte_women_female, pte_lower_women_female, pte_upper_women_female,
chart_type="bar",
title="Women's Email vs Control\nWomen's Merch. Purchasers",
xlabel="Spending Category ($)", ylabel="Probability Treatment Effect",
color="green", ax=ax2)
ax2.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plt.tight_layout()
plt.show()
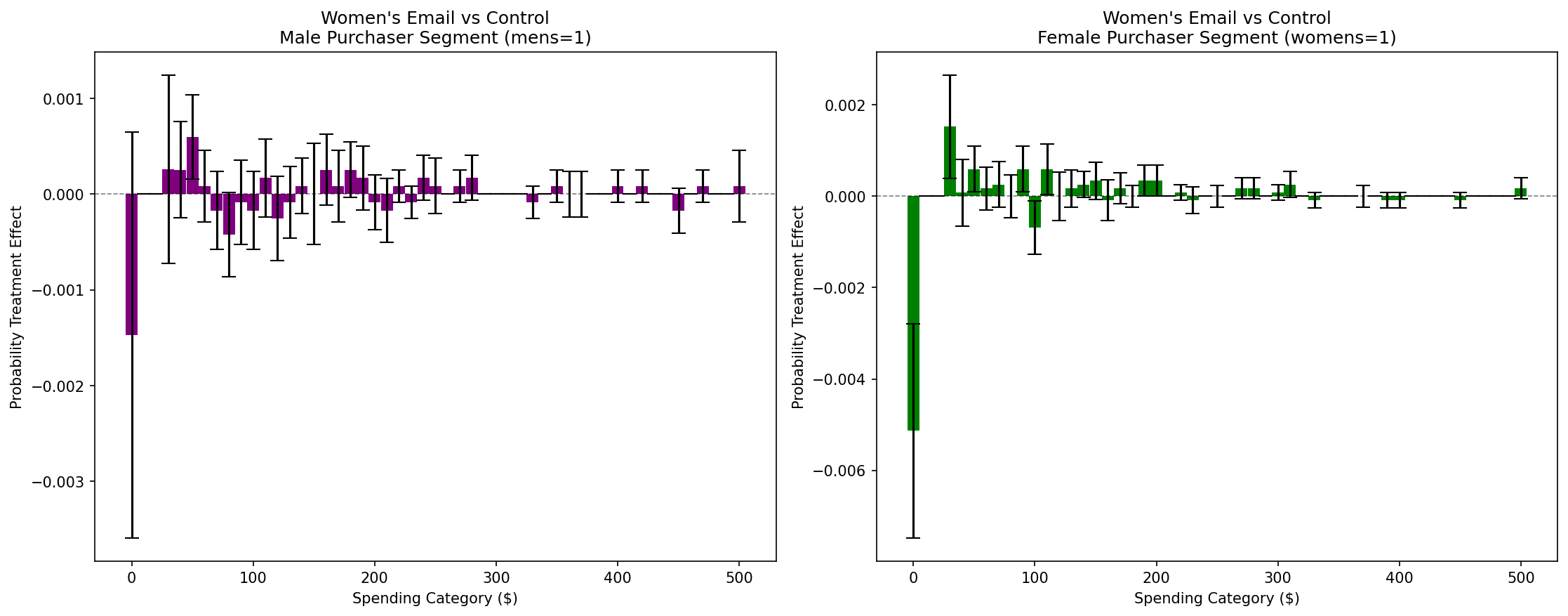
Interval-Specific Insights: The PTE bar charts reveal the mechanism behind the average treatment effect. For women’s merchandise purchasers (right panel), women’s emails significantly reduce the probability of zero spending (non-purchasers converting to purchasers), which is the primary driver of the positive ATE. However, no significant increase in high spending categories is observed. For men’s merchandise purchasers (left panel), the effects are much smaller and less consistent, confirming the limited impact suggested by the ATE and DTE analyses.
Probability Treatment Effects: Men’s Email Campaign¶
Let’s examine which spending categories are most affected by men’s email campaigns:
# Compute PTE for Men's Email vs Control in each subgroup
pte_men_male, pte_lower_men_male, pte_upper_men_male = estimator_male.predict_pte(
target_treatment_arm=1, # Men's Email
control_treatment_arm=0, # No Email
locations=pte_locations,
variance_type="moment"
)
pte_men_female, pte_lower_men_female, pte_upper_men_female = estimator_female.predict_pte(
target_treatment_arm=1, # Men's Email
control_treatment_arm=0, # No Email
locations=pte_locations,
variance_type="moment"
)
# Visualize side-by-side with bar charts
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
plot(locations, pte_men_male, pte_lower_men_male, pte_upper_men_male,
chart_type="bar",
title="Men's Email vs Control\nMen's Merch. Purchasers",
xlabel="Spending Category ($)", ylabel="Probability Treatment Effect",
color="purple", ax=ax1)
ax1.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plot(locations, pte_men_female, pte_lower_men_female, pte_upper_men_female,
chart_type="bar",
title="Men's Email vs Control\nWomen's Merch. Purchasers",
xlabel="Spending Category ($)", ylabel="Probability Treatment Effect",
color="green", ax=ax2)
ax2.axhline(y=0, color='black', linestyle='--', linewidth=0.8, alpha=0.5)
plt.tight_layout()
plt.show()
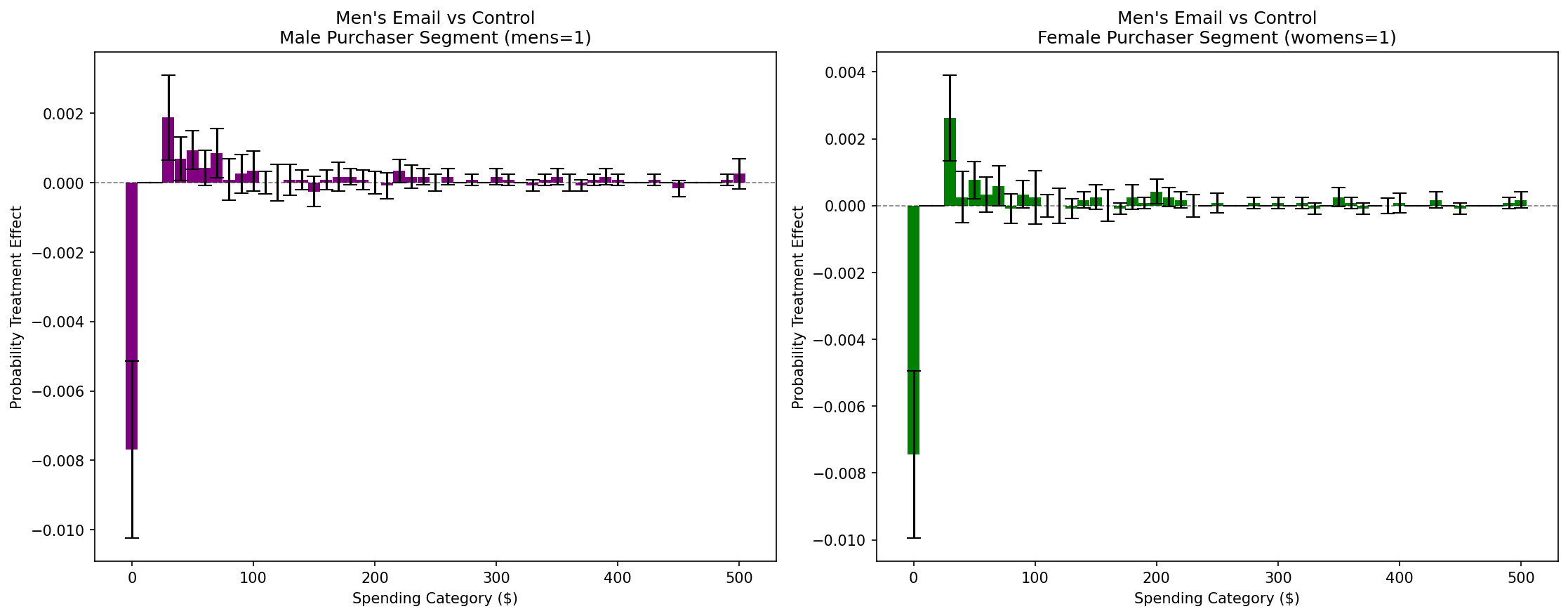
Interval-Specific Insights: Men’s email campaigns show similar PTE patterns across both segments (left and right panels). The key mechanism is twofold: (1) significant reduction in zero spending probability (converting non-purchasers to purchasers), and (2) increased probability in the $40-100 spending range. This dual effect—both purchase conversion and mid-range spending increases—occurs consistently across both male and women’s merchandise purchaser segments, confirming the broad effectiveness of men’s campaigns.
Key Insights from Subgroup Analysis¶
Combining Average Treatment Effects (ATE), Distribution Treatment Effects (DTE), and Probability Treatment Effects (PTE) provides a comprehensive understanding of campaign effectiveness:
1. Campaign Targeting Effectiveness (from ATE)
Women’s email campaigns show 2× stronger average effects for women’s merchandise purchasers ($0.54) vs men’s merchandise purchasers ($0.26)
Men’s email campaigns demonstrate consistent strong effects across both segments ($0.89-$0.84)
This suggests women’s campaigns benefit from precise targeting, while men’s campaigns have broader appeal
2. Distributional Shifts Beyond Averages (from DTE)
For women’s emails, the women’s merchandise purchaser segment shows negative DTE at lower spending thresholds, indicating a systematic shift away from low-spending behavior
Men’s merchandise purchasers show minimal distributional changes from women’s emails, with confidence intervals overlapping zero at most thresholds
Men’s emails produce similar distributional patterns across both segments, confirming broad effectiveness
3. Spending Category Changes (from PTE)
PTE analysis reveals which specific spending intervals change in response to campaigns, particularly identifying the mechanisms behind average effects
Women’s emails: For women’s merchandise purchasers, the primary effect is converting non-purchasers to purchasers (significant reduction in zero spending probability). No significant increase in high spending categories was observed.
Men’s emails: Show a dual mechanism across both segments: (1) converting non-purchasers to purchasers (zero spending reduction), and (2) increasing purchases in the $40-100 range
PTE enables identification of behavioral change mechanisms that are invisible in average treatment effects alone—specifically revealing that lift comes primarily from purchase conversion (0→1 effect) rather than spending increases among existing purchasers
4. Strategic Implications
Based on these findings, several practical implications emerge:
For Women’s Campaigns: Target customers with history of purchasing women’s merchandise to maximize ROI. The PTE analysis reveals that effectiveness comes primarily from converting non-purchasers to purchasers among women’s merchandise purchaser segments, rather than increasing spending among existing buyers.
For Men’s Campaigns: Deploy broadly as they produce consistent positive effects across diverse customer segments. Both male and women’s merchandise purchasers show both purchase conversion and mid-range spending increases, suggesting broader appeal.
Resource Allocation: One practical implication is to prioritize precise targeting for gender-specific content (women’s emails) but invest confidently in broad deployment for broadly appealing content (men’s emails).
5. Methodological Value
This three-tier analysis demonstrates why distributional methods matter:
ATE alone would show that both campaigns have positive effects, but with varying magnitudes across subgroups
Adding DTE reveals how spending distributions shift, not just average changes
Adding PTE pinpoints which spending categories are most affected, enabling precise business decisions
By examining effects at average, distributional, and interval-specific levels, we gain actionable insights that would be invisible to traditional mean-comparison approaches. This demonstrates the power of distribution treatment effect methods for understanding heterogeneous responses in digital marketing experiments.
For the complete reproducible code including helper functions and visualizations, see example/hillstrom.ipynb.
Next Steps¶
Try with your own randomized experiment data
Experiment with different ML models (XGBoost, Neural Networks) for adjustment
Explore stratified estimators for covariate-adaptive randomization designs
Use multi-task learning (
is_multi_task=True) for computational efficiency with many locations